爬山虎采集器電腦版
下載地址
下載地址

爬山虎采集器是一款出色的網頁信息采集軟件,支持99%的網站數據采集。無論您需要從哪個特定網頁中提取數據,這款高效的軟件都能幫助您完成任務。爬山虎采集器具有強大的功能,可以將采集到的數據以多種形式呈現。它能夠生成Excel表格、API數據庫文件等內容,使您能夠更方便地管理和分析網站數據信息,歡迎下載!

向導模式
簡單易用,輕松通過鼠標點擊自動生成
腳本定時運行
可按照計劃定時運行,無需人工
獨創高速內核
自研的瀏覽器內核,速度飛快,遠超對手
智能識別
對于網頁中的列表、表單結構(多選框下拉列表等)能夠智能識別
廣告屏蔽
定制的廣告屏蔽模塊,兼容AdblockPlus語法,可添加自定義規則
多種數據導出
支持Txt 、Excel、MySQL、SQLServer、SQlite、Access、網站等

一鍵提取數據
簡單易學,通過可視化界面,鼠標點擊即可抓取數據
快速高效
內置一套高速瀏覽器內核,加上HTTP引擎模式,實現快速采集數據
適用各種網站
能夠采集互聯網99%的網站,包括單頁應用Ajax加載等等動態類型網站
在本站下載最新安裝包,點擊exe文件,根據安裝向導依次進行安裝
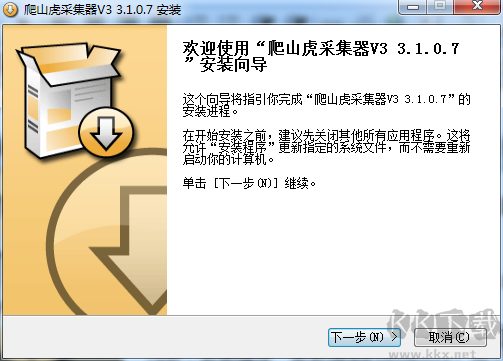
等待安裝完成即可
爬山虎采集器 3.1.0.7
解決部分網站的兼容問題
修復header保存問題
修復其他細節問題
爬山虎采集器 3.1.0.5
修復瀏覽器跨域問題
修復一個驗證碼問題
第一步:輸入采集網址
打開軟件,新建任務,輸入需要采集的網站地址。
第二步:智能分析,全程自動化提取數據
進入到第二步后,爬山虎采集器全自動智能分析網頁,并且從中提取出列表數據。
第三步:導出數據到表格、數據庫、網站等
運行任務,將采集到的數據導出為Csv、Excel以及各種數據庫,支持api導出。

問:如何過濾列表中的前N個數據?
1.有時我們需要對采集到的列表進行過濾,比如過濾掉第一組數據(在采集表格時,過濾掉表格列名)
2.點擊列表模式菜單中的,設置列表xpath
問:如何抓包獲取Cookie,并且手動設置?
1.首先,使用谷歌瀏覽器打開要采集的網站,并且登陸。
2.然后按下 F12,會出現開發者工具,選擇 Network
3.然后按下F5,刷新下頁面, 選擇其中一個請求。
4.復制完成后,在爬山虎采集器中,編輯任務,進入第三步,指定HTTP Header。
 小布地圖工具 v2.4綠色版7.12M
小布地圖工具 v2.4綠色版7.12M 護衛神主機大師 v3.7.5官方版2.91M
護衛神主機大師 v3.7.5官方版2.91M 網易惠惠購物助手 v4.5.0.0官方版4.6M
網易惠惠購物助手 v4.5.0.0官方版4.6M 閃訊 v3.2.8校園專版18.5M
閃訊 v3.2.8校園專版18.5M 九云圖電腦版 v8.3官方版69.4M
九云圖電腦版 v8.3官方版69.4M 美麗折淘客輔助器 v4.9.2免費版300KB
美麗折淘客輔助器 v4.9.2免費版300KB 天天租號平臺上號器 v1180官方版37M
天天租號平臺上號器 v1180官方版37M Bind網卡綁定程序 v1.0免費版11.0M
Bind網卡綁定程序 v1.0免費版11.0M WordPress(博客內容發布系統) V5.7.0中文正式版14M
WordPress(博客內容發布系統) V5.7.0中文正式版14M 瘋狂的美工裝修助手 V36.0破解版29.8M
瘋狂的美工裝修助手 V36.0破解版29.8M返回頂部
Copyright © 2009-2025 KKX.Net. All Rights Reserved .
KK下載站是專業的免費軟件下載站點,提供綠色軟件、免費軟件,手機軟件,系統軟件,單機游戲等熱門資源安全下載!
本站資源均收集整理于互聯網,其著作權歸原作者所有,如果有侵犯您權利的資源,請來信告知

 NetTool IP配置工具 v2.0中文版
NetTool IP配置工具 v2.0中文版 連尚wifi萬能鑰匙pc版安裝包 v4.5.83
連尚wifi萬能鑰匙pc版安裝包 v4.5.83 HostsTool全新版 v3.6.17
HostsTool全新版 v3.6.17 品眾臥龍推廣營銷助手 V1.16.314官方版
品眾臥龍推廣營銷助手 V1.16.314官方版 電腦IP地址修改器 v5.0破解版
電腦IP地址修改器 v5.0破解版 Ultra Adware Killer 中文版v10.8.1
Ultra Adware Killer 中文版v10.8.1 wireshark(網絡抓包工具) v4.2.5
wireshark(網絡抓包工具) v4.2.5